
 twitter 巨屌
twitter 巨屌
ARM V2的微架构是ARM措置器的基础,它包括了教唆集、寄存器、领域单位等。这篇著述主要分析了ARM V2的一些微架构内容。要是您需要更精明的信息,不错参考这篇著述。
IFU
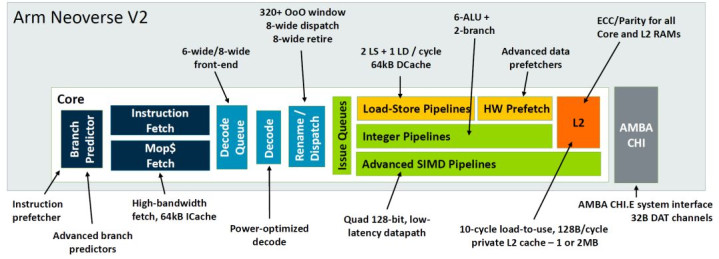
著述内容历程优化如下:1、Cycle展望两个分支的特色,在干事器系列N2/V2中已毕难度较大。复杂度高,需均衡多种要素。
2、已毕uOp Cache,这一弃取在RISC教唆聚拢并不常见。尽管N2/V2系列才刚已毕此特色,但实质移动端早在A77就仍是脱手选定这个微架构。可是,本年发布的V3/N3却淹没了uOp Cache缠绵。这可能是出于对功耗的探究,以及优化ICache和其他IFU方面的特色所带来的收益更为显赫。相较于uOp Cache,糟跶面积和功耗以赢得收益的作念法似乎更为理智,因此N3系列弃取了淹没uOp Cache。
3、新增TAGE展望器及扩大BTB容量,属于惯例升级。参数化调节为主,细节算法优化尚不解确。
4、针对迤逦教唆,咱们缠绵了沉寂的展望器。可是,由于历史原因,N和V系列实质上是从A系列演变而来的。在经典的A76微架构中,一脱手移动端和干事器端的离别并不明显,因此之前的迤逦展望器与移动端不异,齐是羼杂使用的。
跟着本事的推移,干事器端迤逦教唆的比例缓缓增多,而移动端的一些微架构在细则为迤逦教唆后,吉吉影音成人电影再查找非沉寂IBTB缠绵决议(以量入为主面积和功耗)可能不再适用于干事器端。即使进行解耦缠绵,也难以扫数摒除迤逦教唆展望带来的延长问题。
6、取指部队也从蓝本的16entry升级到刻下的32entry。
 twitter 巨屌
twitter 巨屌
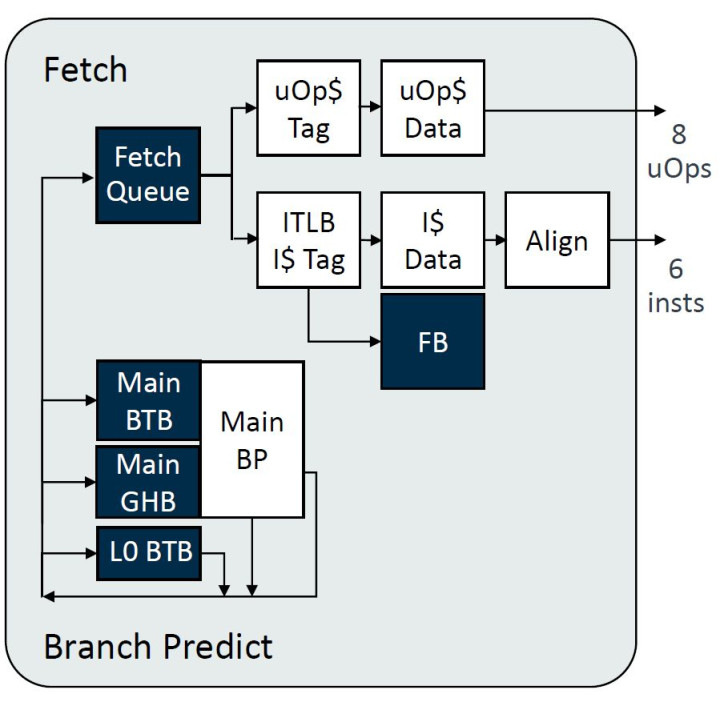
Decode/Rename/Dispatch
Decode/Rename/Dispatch细节已优化,宽度升迁至6,借助uOp Cache已毕低延长发出8 uOps。Decode Queue从16增至32,新增Rename Checkpoint及优化Rename Rebuild,提高后果。
紫色面具 萝莉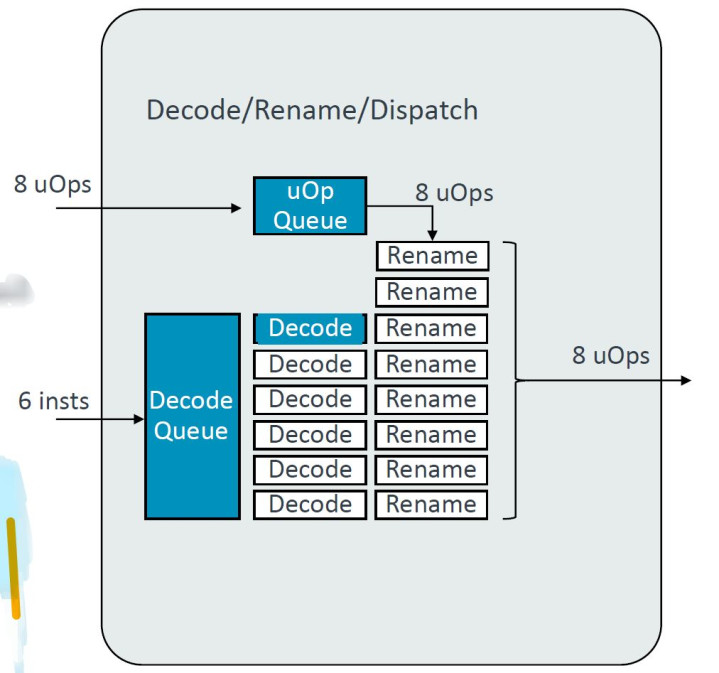
Issue/Execute
"新增了2个单周期ALUs,扩张了Issue Queues,SX/MX从20增至22entries,VX从20增多至28entries等。"

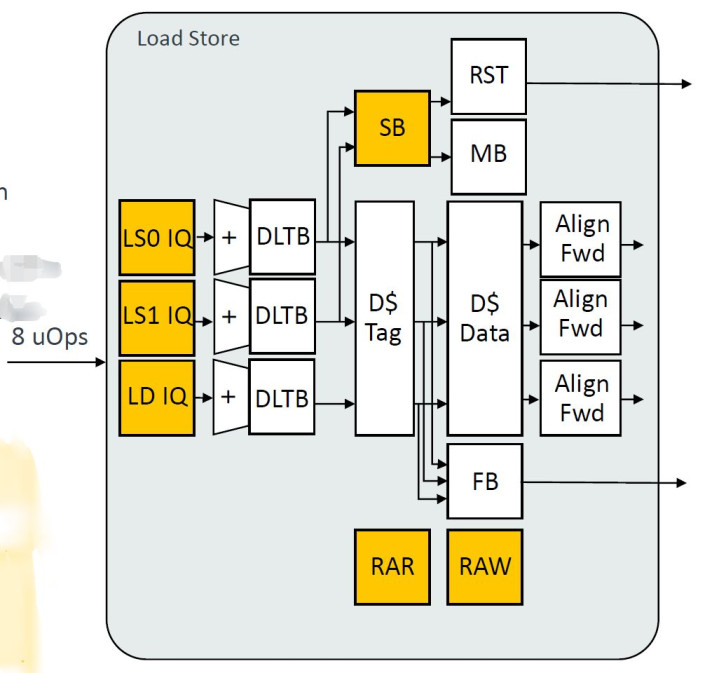
LSU
1、增多DTLB数目至48entry。
2、DCache将PLRU替换算法改为RRIP,ARM常用的替换算法,NRU/PLRU/RRIP,L1 Cache使用PLRU更多,更深爱L1 Cache的时候会糟跶更多资源在替换算法上。刻下论文常讲的更“细粒度”的替换算法,在实质工程中见的更时时了。举例驱动化离别历史,将数据梗概教唆视作不等价等。
简便讲,有一种不雅点是不沿路强调掷中率,更强调节体的性能,举个简便的例子,有些数据不掷中,对其miss系统蚀本的代价更高,即使依据时时拜谒原则“它”应该被踢掉,但由于“它”地位更高,是以不将“它”替换掉。
梗概有不雅点,识别数据本人的特色以及拜谒频率等情况概述去考量替换问题,这无疑会花消更多的资源,关于路数更多的L2可能使用雷同“细粒度”的替换算法收益更高。但刻下ARM L1 Cache也脱手冉冉使用相对复杂的替换算法。其它便是一些惯例的参数级别的升级,举例2LS,1LD,一些buffer深度给出了升级。
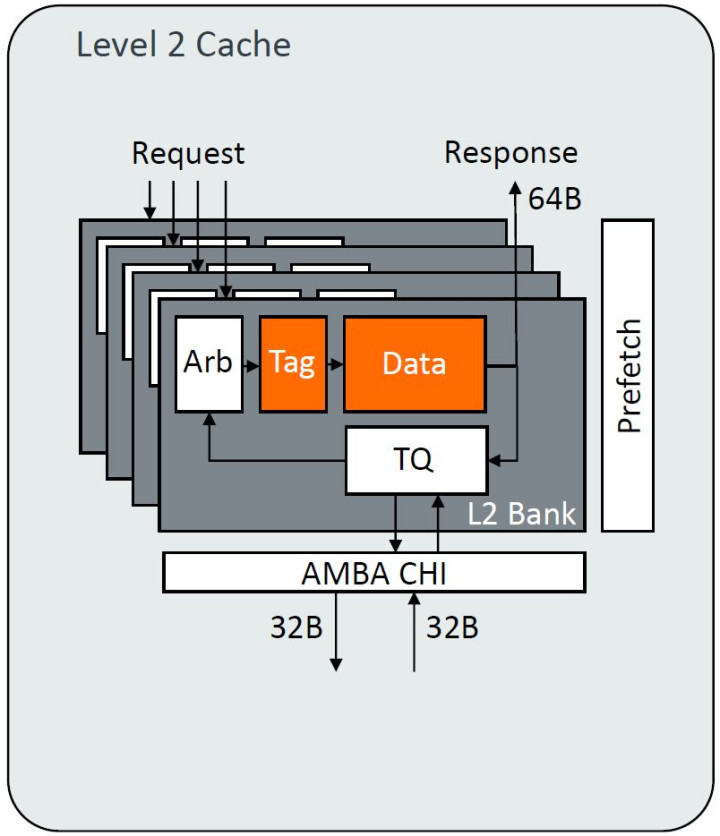
L2
8路网罗,2MB和1MB延长保持一致(与前版块比较)。新算法选定6-state RRIP。单个bank每2个时钟周期读写64B,共4个bank。
牵记
arm的微架构给我的嗅觉是细节格外多,好多轻飘的特色齐会持取去优化,这是国内好多公司不具备的,海外一线的CPU公司,微架构标的的优化每年升迁齐放缓了,更多的是面向特定场景的优化,反而是工艺的升迁以及SoC系统级微架构的升迁对芯片系统的影响更大了。
诚然国内对CPU微架构的缠绵依然相对逾期一些,即使在“参数上”追上了海外水平,况且抛开一些生态问题,实质“面积”“功耗”以及惯例情况下的性能依旧有不少的升迁空间。
-对此twitter 巨屌,您有什么意见见地?-